Python 中的 Async IO (译)
原文由 Brad Solomon 发表于 Jan 16, 2019 ,原文链接: Async IO in Python: A Complete Walkthrough 。
- 配置你的环境
- 远看 Async IO
- asyncio 包和 async/await
- Async IO 设计模式
- Async IO 源自生成器
- 一个完整程序:异步请求
- 上下文中的 Async IO
- 琐碎事情
- 总结
- 资源
Async IO 是一种在 Python 中获得专门支持的并发程序设计,从 Python 3.4 到 3.7 ,发展很快,或许更多。
你可能会担心,“并发,并行,线程,多进程。已经有这么多。那么 async IO 适合什么?”
本教程正是编写来回答这个问题,让你更好的理解 Python 的 async IO 。
这是你将看到的:
- 异步 IO (async IO):一种已经被很多语言实现语言不可知论范式
- async/await :两个用来定义协程的新 Python 关键字
- asyncio :提供运行和管理协程的基础和 API 的 Python 包
协程(专门的生成器函数)是 Python 中 async IO 的核心,我们将深入研究它们。
开始之前,你要确保已经配置好 asyncio 和本教程中其他库的环境。
配置你的环境
在本文中,你需要使用 Python 3.7 或以上版本,还有 aiohttp 和 aiofiles 包:
1 | python3.7 -m venv ./py37async |
如果安装 Python 3.7 和配置虚拟环境过程中需要帮助,可以查看 Python 3 安装配置入门 或 虚拟环境入门。
准备好了,我们开始。
远看 Async IO
Async IO 没有多进程和线程有名。这一节给你一个 async IO 的全景,它如何适应周边景观。
Async IO 适合什么?
并发和并行是不容易介入的广泛的主题。虽然本文重点是 async IO 和它在 Python 中的实现,为了引出 async IO 如何适应更大,有时令人混乱的难题,比较 async IO 和其他并发仍然是值得的。
并行 表示同一时间多个操作。 多进程 是实现并行的一种方法,它需要扩展任务到电脑的 CPU 上。多进程非常适合 CPU 密集型任务:密集的 for 循环和数学计算一般就是这种类型。
并发 是一个比并行更广的术语。它表示多任务可以以重叠的方式运行。(有种说法,并法并不意味着并行。)
线程 是一种通过多线程轮流执行任务的并发执行模型。一个进程可以包含多个线程。由于 GIL , Python 和线程有复杂的关系,不过这超出了本文范围。
需要知道的是线程更适用于 IO 密集型任务。 CPU 密集型任务是电脑内核从开始到结束不停工作, IO 密集型工作是很多等待输入/输出完成。
概括起来,并发包含多进程(适用于 CPU 密集型任务)和线程(适用于 IO 密集型任务)。多进程是并行的一种形式,并行是并发的一种特殊形式(子集)。通过 multiprocessing, threading 和 concurrent.futures 包, Python 标准库已经长时间支持并发。
现在是时候给它们引入一个新成员。过去几年,一个独立的设计更全面地引入 CPython :异步 IO ,通过标准库中的 asyncio 包和新的关键字 async 和 await 。需要指出, async IO 不是一个新创造的概念,它早就存在,并已经引入其他语言和运行时环境,比如 Go, C# 或 Scala 。
Python 文档中, asyncio 包是 一个写并发代码的库 。不过, async IO 不是线程,也不是多进程。也不是在它们之上建立的。
事实上, async IO 是一种单线程,单进程设计:它使用 协作式多任务 ,读完本教程将会很清楚这个术语。换一种说法, async IO 给了一种并发的感觉,尽管使用单线程在单进程中。协程(async IO 的一种重要特征)可以并发的安排,但是它们不是天生的并发。
重复一下, async IO 是并发编程的一种形式,但它不是并行。相比多进程,它更靠近线程,但是它跟它们完全不同,在并发的各种方法中是一个单独的成员。
还有一个术语。 异步 是什么意思?这不是一个严格定义,但是为了我们这里的目标,我想到两个特点:
- 异步程序可以“暂停”,在等待最后的结果时,同时让其他程序运行
- 通过上面的机制,异步代码促进并发运行。换言之,异步代码给了并发的感觉。
这是一个整体示意图。白色术语表示代表概念,绿色术语表示它们实现的方法: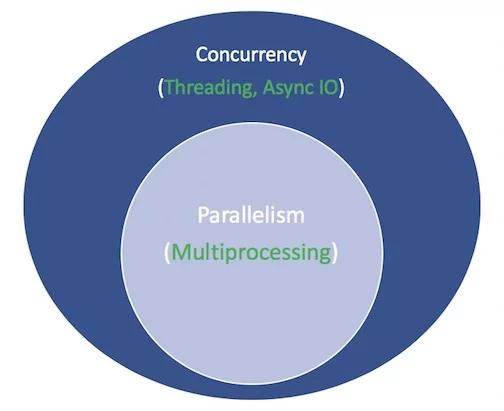
对并发编程模型的比较,到此为止。本教程专注于它的一部分, async IO ,如何使用它,和它周围迅速产生的 API 。想要全面了解线程,多进程和 async IO 的对比,在这暂停并查看 Jim Anderson 的 Python 并发综述 。
Async IO 讲解
Async IO 第一次看起来是反直觉,反常的。一个线程和一个 CPU 内核如果执行并发代码?我一直不擅长举例子,所以转述 Miguel Grinberg 在 2017 PyCon talk 的话,它很巧妙的解释了所有东西:
象棋大师 Judit Polgar 举办象棋车轮战,她和许多陌生选手下棋。她有两种方法安排比赛:同步地和异步地。
假设:
- 24 名对手
- Judit 每步棋用 5 秒
- 对手每步棋用 55 秒
- 比赛平均 30 对移动(共 60 次移动)
同步版本 : Judit 同时只下一场棋,不同时两场,直到比赛结束。每场比赛用时
(55+5)*30 == 1800秒,或者 30 分钟。整个比赛用时24*30==720分钟,或者 12 小时 。
异步版本 : Judit 从一桌到一桌,每桌一次移动。她离开桌,让对手在等待时间走下一步。全部对 24 场比赛走一步用时24*5 == 120秒,或者 2 分钟。整个比赛缩减到120*30 == 3000秒,或者只用 1 小时 。
只有一个 Judit Polgar ,两只手,同一时间只能走一步。但是异步地下棋将比赛时间从 12 小时减小到 1 小时。所以,协作式多任务是一个有效的方法,程序的事件循环与多个任务通信,让每个任务交替,在合适的时间运行。
Async IO 使用长等待期,函数会阻塞,允许其他函数在下线时间运行。(一个阻塞函数从开始到返回,实际上禁止其他运行。)
Async IO 并不简单
我听说,“如果可以,使用 async IO ;如果必须,使用线程。”真相是,建立长期的多线程代码很困难而且容易出错。 Async IO 避免了一些可能在线程设计中遇到障碍。
但是并不是说 async IO 简单。注意:当你深入了解它, async 编程也很困难! Python 的 async 模型建立在一些概念上,比如回调,事件,传输,协议和期物——仅这些术语就很吓人。事实上, API 不断改变使它更难。
幸运地, asyncio 已经成熟,它的许多特点不再暂时,同时文档彻底检查,关于它的一些高质量资源也开始出现。
asyncio 包和 async/await
现在你在设计方面,了解了一些 async IO 的背景,我们来研究 Python 的实现。 Python 的 asyncio 包(在 Python 3.4 引入)和它的两个关键字, async 和 await ,服务于不同目标,但是一起帮你定义,创建,执行,管理异步代码。
async/await 语法和原生协程
async IO 的核心是协程。协程是 Python 生成器函数的专有版本。让我们从基础定义开始,然后随着进程扩展它:协程是一个函数,可以在到达 return 之前暂停执行,有时候它直接传送控制给另一个协程。
随后,你将深入了解传统的生成器如何重新设计为协程。现在,理解协程工作最简单的方法是开始创建一些。
让我们采用沉浸式教学,编写一些 async IO 代码。这段程序是 async IO 的 Hello World ,但是为了说明它的核心功能绕了很长的路:
1 | #!/usr/bin/env python3 |
当你运行这个文件,注意和如果只用 def 和 time.sleep() 定义函数有什么不同:
1 | python3 countasync.py |
这里的输出顺序是 async IO 的关键。讨论每次 count() 调用是一个事件循环,或者协调者。当每个任务到达 await asyncio.sleep(1) ,函数对事件循环大喊,将控制交还给它,“我去睡 1 秒。继续,同时让有意义的事情先做。”
与同步版本对比:
1 | #!/usr/bin/env python3 |
执行时,顺序和执行时间有一个轻微但严重的变化:
1 | python3 countsync.py |
虽然使用 time.sleep() 和 asyncio.sleep() 看起来差不多,它们表示等待。(等待的最平常的就是 sleep() 调用,它基本上什么也不做。)也就是说, time.sleep() 可以代表任何时间消耗阻塞函数调用,而 asyncio.sleep() 用来表示非阻塞调用(但是也需要一些时间来完成)。
你将在下节看到,等待事物的好处,包括 asyncio.sleep() ,是包围函数可以临时放弃控制给其他函数,让其他函数更容易地直接做一些事。相反, time.sleep() 或任何阻塞调用不适用异步 Python 代码,因为它在睡眠时间持续过程中停止任何事。
Async IO 规则
现在,更常用的定义 async, await 和协程函数是按顺序的。本节比较深入,但是掌握 async/await 很重要,所以你需要的时候可以回到这里:
async def语法引入一个 原生协程 或 异步生成器 。表达式async with和async for也是合法的,你将在后面看到它们。await关键字传送函数控制给事件循环。(它暂停包围协程的执行。)如果 Python 在g()范围内遇到一个await f()表达式,这是await告诉事件循环,“暂停执行g()直到f()的结果返回。同时,让其他事情运行。”
第二个特点用代码表示大概像这样:
1 | async def g(): |
何时如何使用 async/await 也有严格的规则。这些很方便,无论你仍然在学习语法或已经使用 async/await :
- 使用
async def引入的函数是一个协程。它可以使用await,return或yield,但是都是可选的。定义async def noop(): pass也是合法的:- 使用
await和/或return创建一个协程函数。为了调用协程函数,你必须await它来获得结果。 - 在
async def块中使用yield并不常见(最近才在 Python 中合法)。这创建一个 异步生成器 ,你可以使用async for来迭代。暂时忘记异步生成器,专注于协程函数语法,使用await和/或return。 - 任何使用
async def定义的不能使用yield from,这将引起语法错误。
- 使用
- 就像在
def函数外使用yield引起语法错误,在async def协程外使用await也会引起语法错误。你只能在协程体内使用await。
这是一些简单的例子,来总结上面的规则:
1 | async def f(x): |
最后,当你使用 await f() , f() 必须是一个 可等待 的对象。好吧,这没有什么帮助,是吗?现在,只需要知道可等待对象是 (1) 另一个协程或者 (2) 一个定义了 .__await__() 特殊方法返回一个迭代器的对象。写程序时大部分情况下,你只需要考虑第 1 种情况。
它带给我们另一个你可能看过的技术区别:一种使函数成为协程f方法是使用 `@asyncio.coroutine装饰一个平常的def` 函数。它的结果是 基于生成器协程 。随着 async/await 语法在 Python 3.5 加入,这种结构已经过期。
这两种协程本质上是一样的(都是可等待的),但是第一种是 基于生成器的 ,而第二种是 原生协程 :
1 | import asyncio |
如果你自己写代码,更应该使用原生协程,为了明确而不是隐含。基于生成器的协程将在 Python 3.10 中移除。
本教程的后半部分,我们只会使用基于生成器协程用于解释目的。引入 async/await 的目的是为了使协程作为 Python 独立的特性,可以方便地与正常生成器函数区分,并减少歧义。
不要使用基于生成器协程,它已经通过 async/await 故意过期。它们有自己的规则(例如, await 不能在基于生成器协程中使用),跟遵守 async/await 语法f什么关系。
不废话,我们看一些更深入的例子。
这个例子说明 async IO 如何减少等待时间:协程 makerandom() 不断产生在 [0, 10] 范围内的随机整数,直到其中一个超过门槛,你想让这个协程的多个调用不需要等待其他完成。你可以根据上面两个脚本的形式,做出一点修改:
1 | #!/usr/bin/env python3 |
输出的颜色比我说更有用,它给你一个脚本运行的感觉:
这个程序使用主协程, makerandom() ,通过 3 个不同的输入并发地运行它。大多数程序包含小的,模块化的协程,和一个用来将协程链在一起的包裹函数。 main() 通过将中心协程对应一些迭代器或池来聚集任务(futures)。
在这个例子中,池是 range(3) 。在后面的完整示例中,它是一系列 URL 需要请求,解析,执行并发地,和 main() 为每个 URL 包含整个协程。
虽然“生成随机整数”(是 CPU 密集型)或许不是 asyncio 最好的选择, asyncio.sleep() 在这个例子中用来在没有明确等待时间引入的情况下,模拟一个 IO 密集型程序。比如, asyncio.sleep() 调用可以代表发送接收不那么随机的整数在消息应用的两个客户端中。
Async IO 设计模式
在本节中,你将了解到 async IO 带来自己的脚本设计。
协程链
协程的一个关键特点是它们可以链在一起。(记得,协程对象是可等待的,所以其他协程可以 await 它。)这允许你将程序分成小的,可管理,可重用的协程:
1 | #!/usr/bin/env python3 |
注意它的输出, part1() 睡眠一段时间, part2() 在结果可用时开始运行。
1 | python3 chained.py 9 6 3 |
在这个配置中, main() 的运行时间等于任务一起并按顺序的运行的最大时间。
使用 Queue
asyncio 包提供 队列类 ,设计为类似 队列 模块类。在我们的例子中,还没有使用队列结构。在 chained.py ,每个任务(future)编排一系列协程,显式的等待其他,每个链传送一个输入。
有另一种结构可以跟 async IO 一起使用:一些相互没有关联的生产者,添加项目到队列中。每个生产者可能添加多个项目到队列,在错开的,随机的,未预期的时间。当项目出现时,一组消费者从队列中拉项目,贪婪地而且不需要等待任何其他信号。
这种设计中,没有任何独立消费者到生产者的链。消费者事先不知道生产者的个数,甚至将添加到队列里累计的项目数。
独立的生产者或消费者花费不同的时间分别在队列中放入取出项目。队列充当一个流量中介,可以让生产者和消费者在不直接面对的情况下通信。
这个程序的同步版本看起来很消极:一组阻塞的生产者按顺序添加项目到队列中。只有等所有生产者完成,队列才可以运行,每次一个消费者运行。这种设计有很大的缺陷。项目可能空闲在队列中,而不是被拿出直接执行。
下面的异步版本, asyncq.py 。这个流程的挑战是当生产已经完成后需要信号通知消费者。否则,等待 q.get() 将无限期挂起,因为队列已经全部执行,但是消费者不知道生产已经完成。
()
这是完整脚本:
1 | #!/usr/bin/env python3 |
开始的协程是帮助函数,返回随机字符串,小数秒性能计数器,随机整数。生产者将 1 到 5 个项目放进队列。每个项目是一个元组 (i, t) , i 是随机字符串, t 是生产者将元组放入队列的时间。
当消费者拉取一个项目,它简单地计算项目在队列中过去的时间,使用项目放入时的时间戳。
记住, asyncio.sleep() 用来模拟其他,更复杂的协程,如果它是正常阻塞函数,它将耗尽时间,阻塞其他执行。
这是使用两个生产者,五个消费者的测试:
1 | python3 asyncq.py -p 2 -c 5 |
这种情况下,项目一瞬间运行。延时有两个原因:
- 标准,不可避免的管理时间
- 当项目出现在队列中时,所有消费者睡眠的情况
关于第二个原因,幸运地,扩展到成百上千的消费者表现完美。你使用 python3 asyncq.py -p 5 -c 100 也没有问题。关键点是,理论上,你可以有不同的用户在不同的系统,控制管理生产者和消费者,队列充当中央流量中介。
目前为止,你已经了解协程,看到三个与 asyncio 相关的例子,调用用 async 和 await 定义的协程。如果你没有完全跟上,或者想更深入了解 Python 中现代协程产生的机制,你将从下一节开始。
Async IO 源自生成器
前面,你已经看到旧式的基于生成器协程的例子,被更显式的原生的协程淘汰。那个例子值得重新看一下:
1 | import asyncio |
测试一下,如果你直接调用 py34_coro() 或者 py35_coro() ,不使用 await ,也不使用 asyncio.run() 或者其他 asyncio “porcelain” 函数?单独调用协程将返回一个协程对象:
1 | py35_coro() |
表面上看并没什么意义。调用协程结果是可等待的 协程对象 。
希望你已经想到 生成器 是这个问题的答案,因为在底层协程是加强的生成器。在这点上行为时类似的:
1 | def gen(): |
向前面发生的,生成器函数是 async IO 的基础(不论你使用 async def 还是旧式的 `@asyncio.coroutine装饰器来定义协程)。技术上说,比起yield, await 是更类似yield from。(但是记得 yield from x() 只是语法糖,替代x(): yield i` 中的 i 。)
生成器的一个关键特性适用于 async IO 是它们任何时刻可以有效地停止,重启。比如,你可以使用打断生成器对象的迭代,之后在剩余的值上恢复迭代。当一个生成器函数到达 yield ,它生成那个值,然后空闲下来,直到通知它生成下一个值。
通过一个例子看更具体:
1 | from itertools import cycle |
await 关键字表现类似,标记一个断点在协程暂停的地方,让其他协程工作。“暂停”,在本例中,意思是协程暂时将控制交出但是没有退出或完成。记住 yield ,和 yield from 和 await ,在生成器执行中标记断点。
这是函数和生成器根本的区别。函数是全部或者没有。一旦启动,在遇到 return 之前它不会停止,遇到之后返回值给调用者(调用它的函数)。另一方面,生成器,每次遇到 yield 时暂停,不再前进。不仅可以将这个值放入调用栈,而且保存他的本地变量,当它被 next() 调用时恢复。
协程第二个比较少知道的特性也很重要。你也可以通过它的 .send() 方法发送值到生成器。这允许生成器(和协程)互相调用(await)而不阻塞。后面,我不再讨论这个特性的更多细节,因为它涉及到协程底层的实现,不过你应该不需要直接使用它。
如果你有兴趣了解更多,可以从 PEP 342 开始,协程最初在这里引入。 Brett Cannon 的 Python 中 Async-Await 到底如何工作 也值得一读,还有 PYMOTW asyncio 评论 。最后, David Beazley 的 协程和并发的求知课程 ,深入协程运行的机制。
我们试着将上面的文章用几句话总结:协程运行有其独特的,非常规的机制。它们的结果是当 .send() 调用时抛出的异常对象的属性。还有更多奇怪的细节,但是对实际使用没有帮助,现在,让我们继续前进。
总结起来,在协程是生成器的讨论中有几个关键点:
- 协程是重新设置的生成器,利用了独特的生成器方法
- 旧的基于生成器协程使用
yield from等待协程结果。现代 Python 语法使用原生协程代替yield from并使用await作为等待协程结果的方法。await类似于yield from,通常它也更符合语义。 - await 是标记断点的信号。它让协程暂停执行,允许程序之后返回。
其他特性: async for 和 Async 生成器 + 解析
除了直接的 async/await , Python 也允许 async for 来遍历 异步迭代器 。异步迭代器的目的是可以当遍历时在每一步调用异步代码。
这个概念一个自然的扩展是 异步生成器 。回想你在原生协程中使用 await , return , 或者 yield 。在 Python 3.6 中(通过 PEP 525),协程使用 yield 成为可能,为了允许 await 和 yield 在相同的协程函数体内使用,引入了异步生成器:
1 | async def mygen(u: int = 10): |
最后, Python 允许使用 async for 的 异步解析 。像同步版的解析,这也是语法糖:
1 | async def main(): |
这里有个很明显的区别: 既不是异步生成器也不是异步解析使迭代并发 。它们所做的是提供类似同步版本的外观,但是使用前面提及的循环的能力来放弃控制给事件循环,使其他协程运行。
换种说法,异步迭代和异步生成器不是用来并发地将一些函数对应到列表或迭代。它们只是让包裹的协程允许其他任务运行。 async for 和 async with 表达式只是扩展 for 和 with 避免“打断”协程中 await 的特性。异步和并发的这个区别是需要掌握的关键点。
事件循环和 asyncio.run()
你可以把事件循环当成类似 while True 的循环,它监控协程,获取空闲协程反馈,同时寻找可以执行的协程。它也能在任何等待协程可用时唤醒空闲协程。
到此,事件循环的全部管理使用一个函数调用来隐式控制:
1 | asyncio.run(main()) # Python 3.7+ |
在 Python 3.7 引入的 [asyncio.run()](https://github.com/python/cpython/blob/d4c76d960b8b286b75c933780416ace9cda682fd/Lib/asyncio/runners.py#L8) ,负责获取事件循环,运行任务直到它们全部完成,然后关闭事件循环。
有一个更冗长的方法来管理 asyncio 事件循环,就是使用 get_event_loop() 。它的典型形式像这样:
1 | loop = asyncio.get_event_loop() |
loop.get_event_loop() 出现在旧示例中,但是除非你有特殊需求,需要细粒度地控制事件循环, asyncio.run() 对于大多数程序都是足够的。
如果你需要在 Python 程序中与事件循环交互, loop 是旧式的 Python 对象,它使用 loop.is_running() 和 loop.is_closed() 支持内省。如果需要更细粒度的控制,你可以控制它,比如在 安排回调 中,将 loop 作为参数传递。
更重要的是理解事件循环底层机制。这里强调事件循环几个关键点。
#1: 协程自己不做什么,直到它们绑定到事件循环上。
你在前面的生成器说明中也看到了这一点,但是仍然值得重申。如果你有主协程等待其他,单独地简单调用它没什么用:
1 | import asyncio |
记住使用 asyncio.run() 真正地执行,通过在事件循环中安排 main() 协程(future 对象)执行:
1 | Hello ... |
(其他协程可以被 await 执行。只需要将 main() 放入 asyncio.run() , await 的链式协程将会执行。)
#2: 默认情况下, async IO 事件循环运行在一个线程一个 CPU 内核上。通常,这样是足够的。不过也可以在多个内核上运行事件循环。查看 John Reese 的演讲 了解更多,但是小心你的电脑可能会自燃。
#3: 事件循环是可插拔的。也就是说,如果需要的话,你可以编写自己的事件循环实现,让它一样运行。在 [uvloop](https://github.com/MagicStack/uvloop) 包里有精彩的演示,它是 Cython 中的一种事件循环实现。
术语“可插拔事件循环”的意思是:你可以使用任何事件循环实现,而与协程本身结构无关。 asyncio 包有 两种不同的事件循环实现 ,默认的是基于 selectors 模块。(第二种实现只是用于 Windows 。)
一个完整程序:异步请求
你已经到了这里,现在是有趣的部分。在本节中,你将建立一个网站抓取 URL 收集器, areq.py ,使用 aiohttp ,一个极快的异步 HTTP 客户端/服务端框架。(我们只使用客户端部分。)这个工具可以用来在一系列网址上对应连接,这些链接形成一个有向图。
程序整体结构像这样:
- 从本地文件 urls.txt 读取一系列 URL
- 发送 GET 请求,解码结果内容。如果失败,对这个 URL 停止。
- 从返回的 HTML 中的 href 标签中搜索 URL 。
- 将结果写入 foundurls.txt 。
- 尽量异步和并发地做上面的步骤。(使用 aiohttp 来请求,和 aiofiles 来写入文件。它们是两个主要的 IO 示例,很适合 async IO 模型。)
这是 urls.txt 的内容。不是很大,包含大多数高流量网站:
1 | cat urls.txt |
列表中的第二个 URL 应该返回 404 ,你应该优雅处理。如果运行更详细的版本,你需要处理更多的问题,比如服务器中断,无限重定向。
请求应该使用一个 session ,利用 session 内部连接池重用。
让我们看看整个程序。随后,我们将一步步深入:
1 | #!/usr/bin/env python3 |
这个脚本比最初的玩具程序要长,所以我们来分解一下。
常量 HREF_RE 是正则表达式寻找 HTML 中的 href 标签来提取最终的结果:
1 | HREF_RE.search('Go to <a href="https://realpython.com/">Real Python</a>') |
协程 fetch_html() 是包裹 GET 请求,发出请求和解码结果页的 HTML 。它发出请求,等待返回,在非 200 状态的情况下抛出对应的异常。
1 | resp = await session.request(method="GET", url=url, **kwargs) |
如果状态是可用, fetch_html() 返回网页 HTML (一个字符串)。很大程度上,在这个函数中没有异常。这里的逻辑是传播异常给调用者,让它去处理:
1 | html = await resp.text() |
我们等待 session.request() 和 resp.text() 因为它们是可等待的协程。请求/返回循环成为应用中占用时间的部分,但是使用 async IO , fetch_html() 让事件循环工作在其他快速可用的工作上,比如解析和写入已经获取的 URL 。
协程链的下一个是 parse() ,它等待对 URL 的 fetch_html() ,然后从网页 HTML 中提取所有 href 标签,确保每个都是合法的,并格式化为绝对路径。
不可否认,第二部分 parse() 是阻塞的,但是它包含很快的正则匹配,确保链接成为绝对路径。
在这种特殊情况下,同步代码应该很快和不引入注目的。但是记得在协程中任何行将阻塞其他协程,除非使用 yield , await 或 return 。如果解析是更密集的过程,你需要考虑使用 [loop.run_in_executor()](https://docs.python.org/3/library/asyncio-eventloop.html#executing-code-in-thread-or-process-pools) 在它自己的进程中运行这部分。
下面,协程 write() 获取一个文件对象和一个 URL ,等待 parse() 返回一个解析 URL 集,通过一个异步文件 IO 包 aiofiles ,将每个解析的 URL 和它的源 URL 异步地写入文件。
最后, bulk_crawl_and_write() 充当进入脚本协程链的主入口。它使用一个 session ,为每个从 urls.txt 读取的 URL 创建一个任务。
这是其他需要注意的点:
- 默认的 ClientSession 有一个最多 100 连接的适配器。要改变这个,给 ClientSession 传递一个 asyncio.conneector.TCPConnector 实例。你也可以在每个主机基础上指定限制。
- 你可以指定最长超时时间,对整个 session 或单个请求。
- 这个脚本还使用了
async with,跟 异步上下文 一起工作。我没有给这个概念单独一节,因为同步到异步上下文的过渡很直观。后者必须定义.__aenter__()和.__aexit__()而不是.__exit__()和.__enter__()。你可能已经想到,async with只能在使用async def定义的协程函数中使用。
如果你想更深入,本教程 更详细的文件 上传在 Github ,已经包含注释和文档字符串。
这有全部的执行, areq.py 在 1 秒内对 9 个 URL 获取,解析和保存结果:
1 | python3 areq.py |
它做的很好!作为完整性检查,你可以检查输出的行数。在我的情况下, 626 行,不过这并不是固定的。
1 | wc -l foundurls.txt |
上下文中的 Async IO
现在你已经看了很多代码,让我们回来,考虑什么 async IO 是合适的选择,如何比较来得到结论,或者选择不同的并发模型。
何时为什么 Async IO 是正确的选择?
本教程没有对 async IO ,线程和多进程进行展开。不过,知道什么时后可能是最好的选择是有用的。
async IO 对多进程的较量其实不算是一个真正的比较。实际上,它们能 合作使用 。如果你有多个,快速统一的 CPU 密集型任务(一个例子是在库中的网格搜索,比如 scikit-learn 或 keras),多进程是明显的选择。
如果所有函数使用阻塞调用,那么简单地将 async 放到每个函数器是错误的。(这实际上会减慢你的代码。)但是像前面提到的,有些地方 async IO 和多进程可以 和谐相处 。
async IO 和线程的竞争比较直接。我在简介中提到,“线程很困难。”故事是这样的,即使在线程看似容易实现情况下,由于静态条件和内存使用,或其他情况,它仍然可能导致很差的的不能跟踪的 bug 。
线程也没有 async IO 优雅,因为线程是有限的系统资源。创建上千个线程在大多数机器上都会失败,我首先不推荐尝试。而创建上千个 async IO 任务却完全可行。
Async IO 在有多个 IO 密集型任务有用,任务由在阻塞 IO 等待时间控制,比如:
- 网络 IO ,无论你的程序在服务端或客户端
- 无服务器设计,比如端对端,多用户网络比如群聊天室
- 读写操作你模拟“即发既忘”风格,而不用担心在你读或写之上s锁
不使用它的最大原因是 await 只支持定义了制定方法的特定对象。如果你想异步读取某种关系型数据库,你不只需要找到它的 Python 封装,而且还要支持 async/await 语法。包含同步调用的协程将阻塞其他协程和任务运行。
本教程末有一份使用 async/await 工作的库 列表 。
选 Async IO ,但是选哪个?
本教程聚焦于 async IO , async/await 语法,并使用 asyncio 来管理事件循环和特定任务。 asyncio 当然不是唯一的异步 IO 库。 Nathaniel J.Smith 的观点说明很多:
多年之后, asyncio 或许发现自己降级为一个像 urllib2 一样,熟练开发者避免使用的库。
…
我说的是,实际上, asyncio 是它成功的牺牲品:当它设计时,使用可能的最好的方式;但是从那以后,由 asyncio 激励,像 async/await ,情况有变使我们可以做的更好,现在 asyncio 因为它过早承诺而不能改进。
为此,一些做 asyncio 工作的有名的备选是 curio 和 trio ,尽管使用不同的 API 和不同的方法。个人来看,如果你创建一般大小,简单的程序,只使用 asyncio 已经足够和易懂,让你避免添加很多 Python 标准库以外的依赖。
但是,当然可以,了解 curio 和 trio ,你或许发现它们以一种你觉得更直观的方式做了同样的事情。这里提出的很多与包无关的概念也适应于其他 async IO 包。
琐碎事情
在后面的小结中,你看到之前没有提到的 asyncio 和 async/await 的一些零碎部分,但是对于创建理解整个程序也是重要的。
其他最高级 asyncio 函数
除了 asyncio.run() ,你也看到一些其他包级函数,比如 asyncio.create_task() 和 asyncio.gather() 。
你可以在 asyncio.run() 之后,使用 create_task() 来安排协程对象的执行:
1 | import asyncio |
这种方式有个细微之处:如果你没有在 main() 等待 t ,它可能在 main() 表示完成之前结束。因为 asyncio.run(main()) 调用 loop.run_until_complete(main()) ,事件循环只关心(没有 await t) main() 完成,而不是由 main() 创建的任务完成。没有 await t ,循环的其他任务可能在完成之前 被取消 。如果你需要获取正在暂停的任务列表,你可以使用 asyncio.Task.all_tasks() 。
另外,还有 asyncio.gather() 。虽然它没有做什么特别的事情, gather() 意思是整齐地将一列协程(futures)放入一个 future 。结果,它返回一个 future 对象,如果你 await asyncio.gather() 并指定多任务或协程,你将等待所有它们完成。(有点类似前面例子中的 queue.join() 。) gather() 的结果将是对应输入的一个结果列表:
1 | import time |
你可能注意到 gather() 等待你发送的整个 Futures 或协程的结果。另外,你可以使用 asyncio.as_completed() 来以完成顺序等它们完成循环获取任务。函数返回生成完成任务的迭代器。下面, coro([3, 2, 1]) 结果早于 coro([10, 5, 0]) 完成,不同于 gather() 的情况:
1 | async def main(): |
最后,你也看到 asyncio.ensure_future() 。你很少用到它,因为它是底层 API ,基本被随后引入的 create_task() 取代。
await 的优先权
虽然有些情况下它们行为类似, await 关键字优先级明显高于 yield 。这意味着,因为它更紧密,有很多实例你需要在 yield from 声明加括号,类似的 await 声明则不需要。如果想了解更多,查看 PEP 492 await 表达式示例 。
总结
你现在已经能使用 async/await 和它周围的库。这是简要回顾:
- 异步 IO 是语言无关模型,是一种通过协程之间间接通信的实现并发的方式
- Python 特有的新 async 和 await 关键字,用来表示和定义协程
- Python 包 asyncio 提供 API 来运行和管理协程
资源
Python 版本详情
Python 中的 Async IO 变化很快,很难跟踪什么时候带来什么。这是 Python 小版本变化和关于 asyncio 的引入的列表:
- 3.3 :
yield from表达式允许生成器定义。 - 3.4 : asyncio 以暂定 API 状态引入到 Python 标准库
- 3.5 : async 和 await 成为 Python 语法的一部分,用来标志和等待协程。还不是保留关键字。(你仍可以定义函数或变量使用 async 和 await 。)
- 3.6 :引入异步生成器和异步解析。 asyncio API 宣布由临时变为固定。
- 3.7 : async 和 await 成为保留关键字。(不能再使用它们作为标识符。)它们替代了
asyncio.coroutine()装饰器。asyncio.run()引入到 asyncio 包,还有 一系列其他特性 。
保险起见(也可以使用 asyncio.run()),使用 Python 3.7 或以获得全部特性。
文章
这是一个更多资源列表:
- Real Python : 使用并发加速你的 Python 程序
- Real Python : 什么是 Python 全局解释器锁?
- CPython : asyncio 包 源码
- Python 文档: 数据模型 > 协程
- TalkPython : Python 中 Async 技术和例子
- Brett Cannon : Python 3.5 中的 Async-Await 是怎样工作的?
- PYMOTW : asyncio
- A.Jesse Jiryu Davis 和 Guido van Rossum : 一个使用 asyncio 协程的网络爬虫
- Andy Pearce : Python 协程状态: yield from
- Nathaniel J.Smith : 在后 async/await 世界,对异步 API 设计的一些想法
- Armin Ronacher : 我不懂 Python Asyncio
- Andy Balaam : asyncio 系列 (4 篇文章)
- Stack Overflow : async-await 函数中的 asyncio.semaphore
- Yeray Diaz :
一些 Python 什么新章节解释了语言变化的动机,在更多细节上:
- Python 3.3 新增(yield from 和 PEP 380)
- Python 3.6 新增(PEP 525 & 530)
David Beazly :
YouTube 讨论:
- John Reese - 跳出 GIL 思考 AsyncIO 和多进程 - PyCon 2018
- Keynote David Beazley - 互联网话题(Python Asyncio)
- David Beazley - Python 并发从头开始:直播! - PyCon 2015
- Raymond Hettinger ,并发 Keynote , PyBay 2017
- 理解并发, Raymond Hettinger , Python 核心开发者
- Miguel Grinberg 异步 Python 对新手 PyCon 2017
- Yury Selivanov asyncawait 和 asyncio 在 Python 3.6 和之后 PyCon 2017
- 担忧等待 Async :一个协程梦核心的开荒旅行
- 什么是 Async ,他如何工作,什么时候使用它?(PyCon APAC 2014)
相关的 PEP
| PEP | 创建时间 |
|---|---|
| PEP 342 - 协程通过增强生成器 | 2005-05 |
| PEP 380 - 委托子协程的语法 | 2009-02 |
| PEP 3153 - 支持异步 IO | 2011-05 |
| PEP 3156 - 异步 IO 支持重启: “asyncio” 模块 | 2012-12 |
| PEP 492 - 协程使用 async 和 await 语法 | 2015-04 |
| PEP 525 - 异步生成器 | 2016-07 |
| PEP 530 - 异步解析 | 2016-09 |
使用 async/await 工作的库
从 aio-libs :
- aiohttp : 异步 HTTP 客户端/服务端框架
- aioredis : Async IO Redis 支持
- aiopg : Async IO PostgreSQL 支持
- aiomcache : Async IO memcached 客户端
- aiokafka : Async IO Kafka 客户端
- aiozmq : Async IO ZeroMQ 支持
- aiojobs : 工作协调器,管理后台任务
- async_lru :简单 LRU 缓存对 async IO
从 magicstack :
从其他网站:
- trio :更友好的 asyncio 趋向展示快速简单的设计
- aiofiles : Async 文件 IO
- asks : Async 类 requests http 库
- asyncio-redis : Async IO Redis 支持
- aioprocessing :与 multiprocessing 模块交互 asyncio
- umongo : Async IO MongoDB 客户端
- unsync :非同步 asyncio
- aiostream : 像 itertools ,但是异步的